
I’ve been describing a common thread throughout these posts which is we can spend hours building artisinally crafted seccomp profiles and say that everything is more secure, but we don’t inherently know that. We just assume. And even when we want to measure if a given seccomp profile is “good” there’s an immense amount of complexity to come to that decision.
For instance, to decide if a seccomp profile is “good” we have 1 simple question:
Which system calls does it allow and which does it block?
To get that answer we have to ask more questions:
I think the lack of population-level data is genuinely one of the biggest problems in this space right now – we’re all tuning profiles in the dark. Here’s what we don’t have: public data on what seccomp profiles organizations actually deploy. We can score your profile against the Docker default, but we can’t tell you how you compare to the industry because nobody’s publishing their profiles. Why would they?
This partly why I’ve been running seccompare.com for a year or so. It’s partly an anonymous data collection exercise to figure out how people are using seccomp at scale. What are people uploading? How do those profiles score? The historical timeline shows how Docker’s own default has evolved since 2015 – syscalls added, syscalls blocked, conditional rules refined. Most custom profiles don’t track these changes. They’re frozen in time.
I’ve also been harvesting sources online for OCI seccomp profiles and profiled them. The results of looking at ~800 profiles were interesting to me:
I’ve been saying that seccomp is simple: “block”, “allow” – but that’s kind of a lie, right? Seccomp has this vast amount of conditionals you could apply per system call or per filter. You can say things like “If the first argument of the system call is 2114060288 then allow it, else block”
{
"names": ["clone"],
"action": "SCMP_ACT_ALLOW",
"excludes": {
"caps": ["CAP_SYS_ADMIN"]
},
"args": [
{
"index": 0,
"value": 2114060288,
"op": "SCMP_CMP_MASKED_EQ"
}
]
}
This is granting the container the ability to do the initial clone() on startup but blocking it on all subsequent calls.
Or you can say “If the container has been granted CAP_SYS_ADMIN then allow bpf”.
{
"defaultAction": "SCMP_ACT_ERRNO",
"syscalls": [
{
"names": ["bpf"],
"action": "SCMP_ACT_ALLOW",
"includes": {
"caps": ["CAP_BPF"]
}
},
]
}
This one is pretty practical – if you are granting CAP_BPF then you mind as well allow it to the system calls it needs like bpf. Moby/Docker’s default profile uses this type of conditional extensively.
But looking at the containerd/runc implementation and you’ll see it’s different. Docker leverages the BPF format itself for the conditionals, but containerd generates seccomp profiles dynamically. This is the code from containerd: contrib/seccomp/seccomp_default.go:
// conditionally add bpf if CAP_SYS_ADMIN is set
if !inSlice(s.Capabilities, "CAP_SYS_ADMIN") {
s.Syscalls = append(s.Syscalls, specs.LinuxSyscall{
Names: []string{"bpf", "clone", "fanotify_init", "lookup_dcookie",
"mount", "name_to_handle_at", "perf_event_open",
"quotactl", "setdomainname", "sethostname",
"setns", "syslog", "umount", "umount2",
"unshare"},
Action: specs.ActErrno,
ErrnoRet: &defaultErrno,
})
}
The profile isn’t static JSON — it’s generated at container start based on what capabilities the process will have. Grant CAP_SYS_ADMIN and a completely different profile gets loaded, one that no longer blocks bpf.
Which one is more secure? They’re effectively the exact same. Which one is more auditable? Unless you’re extracting the raw BPF bytecode from the process, you don’t really know for sure which seccomp policy is being applied for your container.
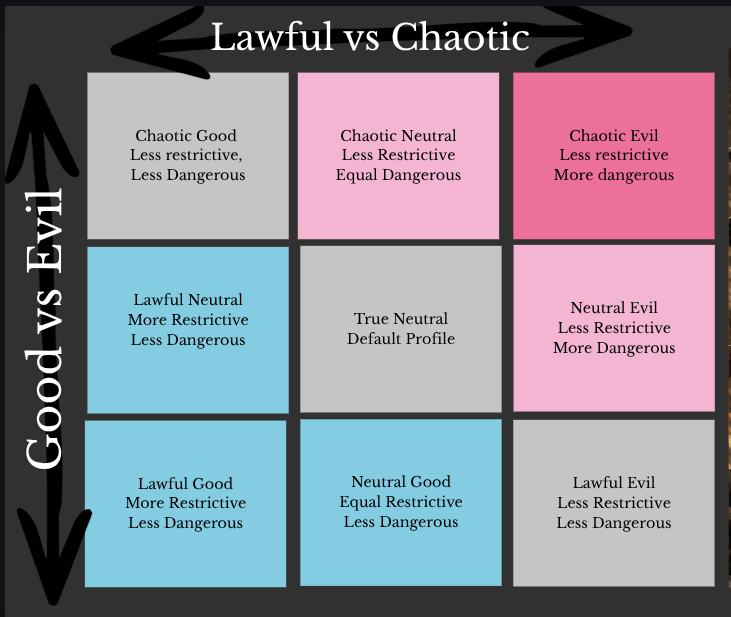
I started out with a naive perspective that there was a bad and good with seccomp profiles. And when I gathered them all together I created charts that like this: Seccomp Profiles Good vs Bad
The problem is good isn’t just based on the number of system calls blocked. Seccomp profiles have at least 2 dimensions that make them good:
So that means the above chart is too simple. We can’t just say that restricting a profile makes it “good” because we still end up situations where it’s more restrive but then it allows bpf(). I like to think of it like a D&D alignment chart (good/evil on one axis, lawful/chaotic on the other):
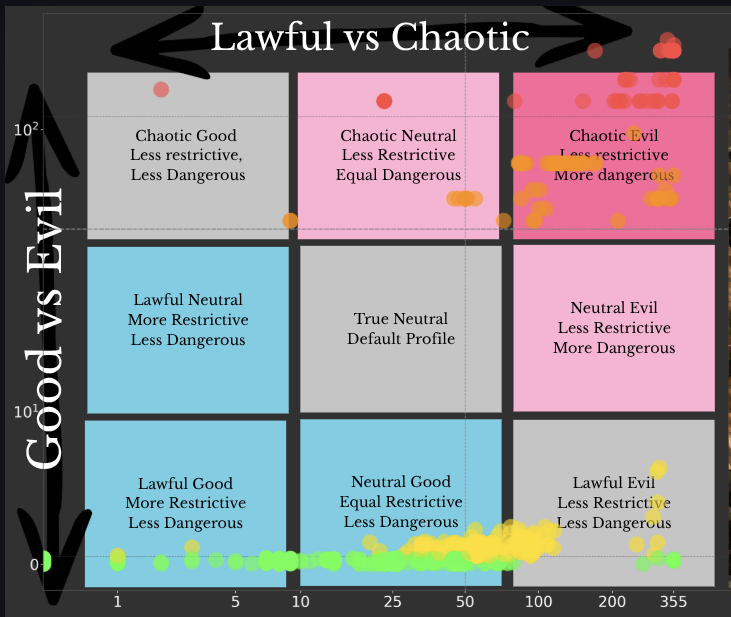
Then there are some interesting types:
bpf()If you take all the profiles I’ve found and overlay them on this grid, you see a interesting mix of very good and well intentioned profiles, but many many other instances of dangerous ones – or at least less secure than the default seccomp profile.
Can we put this together into something we can use?
Knowing what’s in your profiles is one thing. Knowing if they’re any good is another. “I looked at it and it seems fine” is not a scalable review process. Enter seccompute which scores profiles on a 0-100 scale using tier-weighted syscall analysis:
bpf, ptrace, kexec_load, init_module, finit_module. If any of these are allowed, the profile is a failure. I don’t care how many other system calls you’ve blocked, you’ve allowed dangerous things.io_uring_setup, io_uring_enter, perf_event_open, mount, clone, unshare. Each one costs real points because each one enables real attack classes.clone3, chroot, namespace-adjacent syscalls. Still tracked, still scored, but these are the potential enumeration risks rather than the “stop and fix it” tier.You can also use this to compare your profile against the Docker default. A positive delta means you’re more restrictive – good. A negative delta means you’ve made things worse than the default – you should know that before deploying.
If you remember me writing about the multiplexing risks (Seccomp in K8s: Bypasses and Breakouts) then this is where Seccompute gets interesting. seccompute doesn’t just check individual syscalls – it checks combinations against a rule set and contextualizing the risks by including the underlying architecture and capabilities assigned. You can also customize this rulset yourself.
COMBO-io-uring-network-bypass: io_uring_setup + io_uring_enter allowed while network syscalls are blocked means the network blocks are bypassed.COMBO-bpf-escalation: bpf allowed in any form. These patterns don’t show up in a line-by-line review. They require understanding how syscalls interact, which is exactly what a scoring tool should do for you.COMBO-io-uring-file-io-bypass: io_uring_setup + io_uring_enter allowed while file I/O syscalls (read, write, pread64, fsync, etc.) are blocked — file operations bypass the filter.COMBO-io-uring-filesystem-bypass: same pair allows filesystem path operations (openat, unlinkat, renameat, mkdir, symlink, etc.) without touching the blocked syscalls.COMBO-io-uring-poll-bypass: io_uring_enter can submit IORING_OP_POLL_ADD and IORING_OP_EPOLL_CTL, bypassing blocked poll, epoll_wait, epoll_ctl.COMBO-io-uring-splice-bypass: IORING_OP_SPLICE and IORING_OP_TEE bypass blocked splice, tee, vmsplice.COMBO-io-uring-process-bypass: on Linux 6.6+, io_uring_enter can submit IORING_OP_WAITID and futex operations, bypassing blocked futex, waitid, wait4.COMBO-io-uring-ioctl-bypass: IORING_OP_URING_CMD allows device-specific commands (NVMe, ublk) without invoking ioctl(2) directly.COMBO-io-uring-xattr-bypass: xattr get/set/list operations (getxattr, setxattr, listxattr, and their variants) bypass via io_uring_enter.You can run this as a CLI or as part of a library like I do for Seccompare.com. But the pro move would be to integrate it into your CI.
The real challenge of using seccomp is that every line of code, every bump of a dependency, every new node type you deploy to needs to profile the container all over again. That means that seccomp is not a 1 time event. You need to integrate it into your CI pipelines as part of your normal testing.
You can take Seccompute (or rebuild it and make your own, I don’t care) and integrate it into your CI. It could be a Github Action that validates the seccomp profile meets a minimum threshold of a score and if not needs manual human intervention.
My talk at BSidesSF made the point that I specifically wanted to convince people to have stronger opinions about seccomp in Kubernetes.It’s either all in or all out. There are some great organizations that are doing this at scale and doing it well. All of this is to say that seccomp in k8s is harder than it should be. I made the point during the talk that if you need strong isolation, we can go back to the classics: MicroVMs or emulated kernels (ie. gVisor). These are the strongest solutions but have the biggest risks to performance.
I also dropped a few “what-ifs” in the talk that I still think are good ideas if we can get some support on it:
But, if nothing else, my hope is for anyone taking their Certified Kubernetes Security (CKS) Specialist exam or reading materials, please question how far you want to say that seccomp is an every day tool for locking down the environment.
How did I do? The only failure mode for me is after reading through all of this you come away with a tepid perspective on seccomp in Kubernetes. And no, I didn’t use AI to slop this blog together. This is an artisanally crafted blog post filled with my own human errors.
My hope is that this seccomp brain worm can finally get out of my head and stay here on these pages, or enter into yours.
Sandboxes, Seccomp and Syscalls - BSides SF 2026 by Mark Manning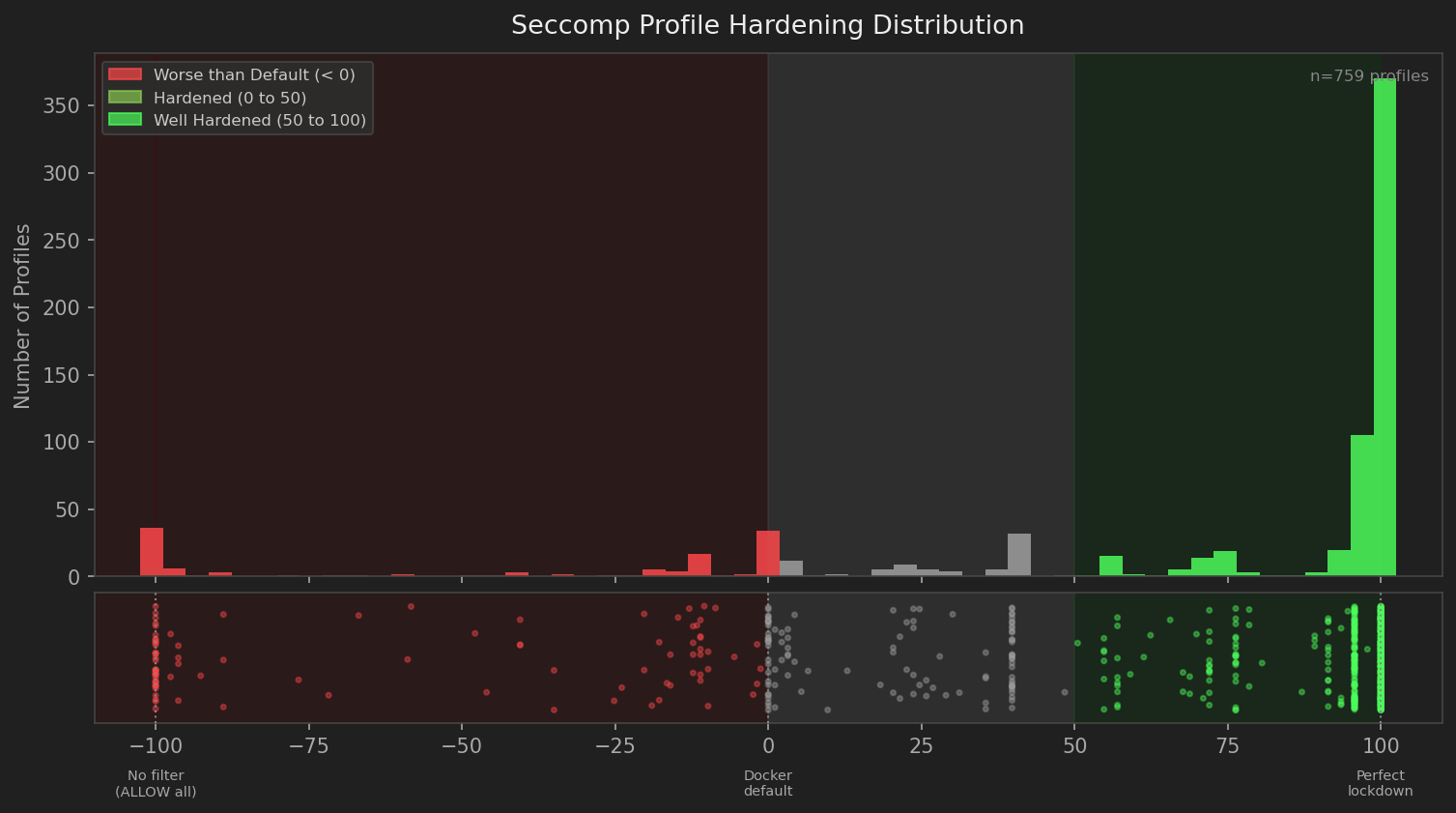{kind=link}